profiling characters

Contents
How to do it
1.Choose one or more texts or a folder. You can type in a complete filename (including drive and folder), and can use wildcards such as *.txt, or you can browse to find your text or folder.
2.If you want to study one text only, just choose one text, but you may choose a whole folderful or more by using the "sub-folders too" option.
3.Press Analyse.
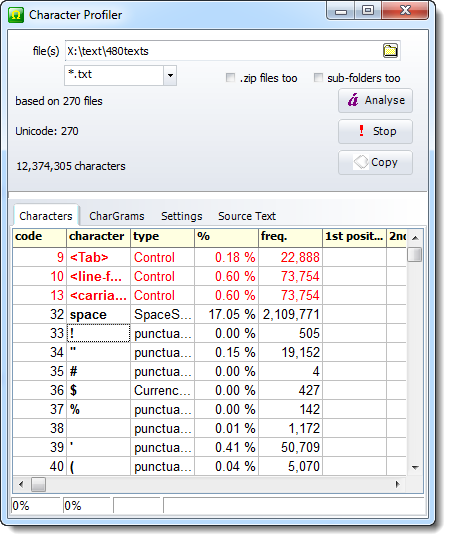
The display shows details of your selected text, and if you click the Source Text tab you can see the original text. (If you have analysed a whole set of text files the Source Text tab will show only that last one.)
Legend
code the Unicode code of
character the character
type distinguishing punctuation, digits, letters
% percentage of the total number of characters in the text(s)
freq. number of occurrences of that character
<Tab> etc. control characters indicated in red.
1st Position number of each letter-character occurring in word-initial position
2nd number found in second position in any word
etc.
Note that 8th will only be able to count letter frequencies for words at least 8 letters long, while 1st or 2nd will handle nearly all words.
Sort
Click the header to sort the data:
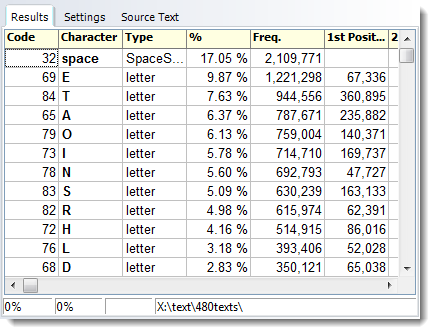
The letter E (upper and lower case merged) here represents nearly ten percent of all letters, closely followed by T. If sorted by 1st position in the word, however,
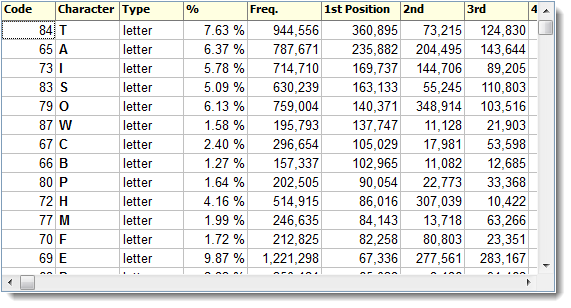
the letter E comes after T,A,I,S,O,W,C,B,P,H,M and F in frequency. Presumably the ranking of T reflects the frequency in English of the and A of a.
Copy
Copies the data to the clipboard, ready to be pasted for example into Excel.
See also: settings