
Settings are found in the main Controller.
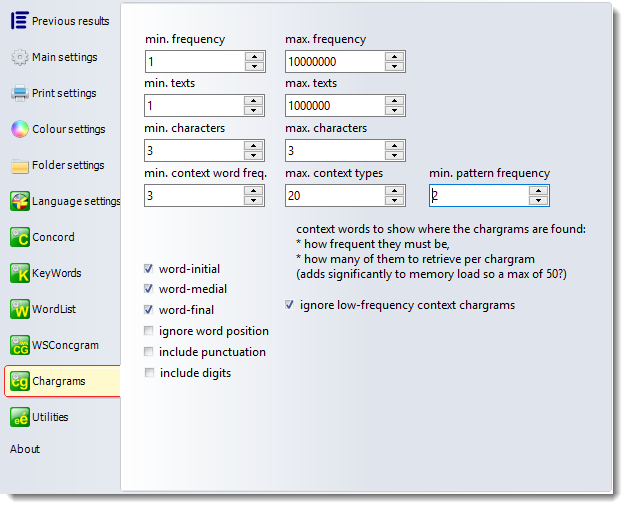
You can set minimum and maximum token frequencies for the chargrams to be included in the results, a minimum and maximum number of texts they must appear in, the length in characters (e.g. 3 to 4 characters).
Context words
As the chargrams are selected, note is taken of the word which they are found in. Here you can determine a minimum number of times for each chargram to appear in a given word for that word to be listed, and a maximum number of context words per chargram to be collected. (Storing lots of extra words will use up system memory so a default of 20 or 50 may be reasonable.
Word position
By default chargrams in all three positions (word-initial, word-medial and word-final) will be collected. If you check the ignore word position box, word positions get merged.
Include punctuation
Allows chargrams of all characters (symbols, punctuation etc.) to be included. Spaces get replaced by underscores.
Include digits
Allows chargrams of digits as well as alphabetic characters.
Ignore low-frequency context chargrams
This setting allows us to filter out any chargrams which do not occur in many contexts. As shown here, any chargrams not occurring in at least 3 context word types will get eliminated. If, for example, a chargram has been found in 5 context word-types then the chargram is included in your list. But if in only 1 of these it is found occurring at least 3 times (i.e. found in the same context word-type recurring in the texts at least 3 times), you will see one context word only in the contexts column
min. pattern frequency
This setting lets you restrict low-frequency patterns.
See also: chargrams display
