
How to do it...
Sorting can be done simply by pressing the top row of any list. Or by pressing F6. Or by choosing the menu option.
The point of it…
The point of re-sorting is to find characteristic lexical patterns. It can be hard to see overall trends in your concordance lines, especially if there are lots of them. By sorting them you can separate out multiple search words and examine the immediate context to left and right. For example you may find that most of the entries have "in the" or "in a" or "in my" just before the search word -- sorting by the second word to the left of the search word will make this much clearer.
Sorting is by a given number of words to the left or right (L1 [=1 word to the left of the search word], L2, L3, L4, L5, R1 [=1 to the right], R2, R3, R4, R5), on the search word itself, the context word (if one was specified), the nearest tag, the distance to the nearest tag, a set category of your own choice, or original file order (file).
Main Sort
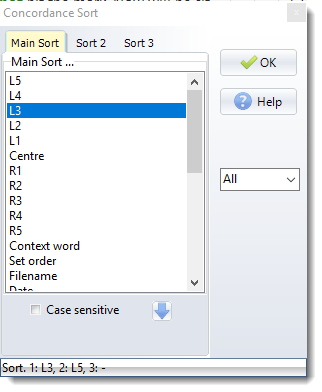
The listing can be sorted by three criteria at once. A Main Sort on Left 1 (L1) will sort the entries according to the alphabetical order of the word immediately to the left of the search word. A second sort (Sort 2) on R2 would re-order the listing by tie-breaking, that is: only where the L1 words (immediately to the left of the search word) matched exactly, and would place these in alphabetical order of the words 2 to the right of the search word. For very large concordances you may find the third sort (Sort 3) useful: this is an extra tie-breaker in cases where the second sort matches.
For many purposes tie-breaking is unnecessary, and will be ignored if the "activated" box is not checked.
default sort
This is set in the main controller settings.
sorting by set (user-defined categories)
You can also sort by set, if you have chosen to classify the concordance lines according to your own scheme, using letters from A to Z or a to z or longer strings. The sort will put the classified lines first, in category order, followed by any unclassified lines. See Nearest Tag for details of sorting by tags. See colour categories for a more sophisticated way of using the Set column.
other sorts
As the screenshot below shows, you can also sort by a number of other criteria, most of these accessible simply by clicking on their column header.
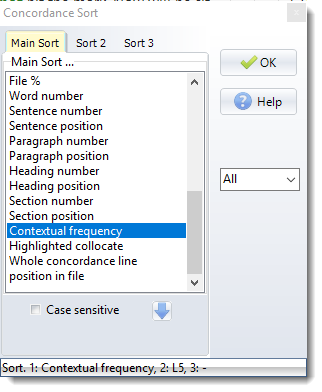
The "contextual frequency" sort means sorting on the average ranking frequency of all the words in each concordance line which don't begin with a capital letter. For this you will be asked to specify your reference corpus wordlist. The result will be to sort those lines which contain "easy" (highly frequent) words at the top of the list.
All
By default you sort all the lines; you may however type in for example 5-49 to sort those lines only.
Ascending or Descending?
Use the ![]() or
or ![]() button to set the sort order is from A to Z, or Z to A.
button to set the sort order is from A to Z, or Z to A.
See also: WordList sort, KeyWords sort, Choosing Language
