
Stop lists are lists of words which you don't want to include in analysis. For example you might want to make a word list or analyse key words excluding common function words like the, of, was, is, it.
Prepare and load up your stop list first, then make your word lists using it. (To use a list to remove items from an existing word list, see the Match list function.)
To use stop lists, you first prepare a file, using Notepad or any plain text word processor, which specifies all the words you wish to ignore. Separate each word using commas, or else place each one on a new line. You can use capital letters or lower-case as you prefer. You can use a semi-colon for comment lines. There is no limit to the number of words. Stop lists do not use wildcards (match-lists may).
There is a file called stop_wl.stp (in your \wsmith7 folder) which you could use as a basis and save under a new name. You'll also find basic_English_stoplist.stp there, based on top frequency items in the BNC. Or just make your own in Notepad and save it with .stp as the file-extension. If that is difficult, rename the .txt as .stp.
Example
; My stop list for test purposes.
THE,THIS,IS
IT
WILL
<VVN>SEEN
You may put angle-brackets in a stop list. So <VVN>SEEN (that is seen as a past participle) will remove any cases of precisely that sequence if it is in your texts. It will only stop seen if marked with <VVN> in the corpus.
Then select Stop List in the menu to specify the stop list(s) you wish to use. Press Load to read it in. Separate stop lists can be used for the WordList, Concord and KeyWords programs.If you wish always to use the same stop list(s) you can specify them in wordsmith7.ini as defaults.
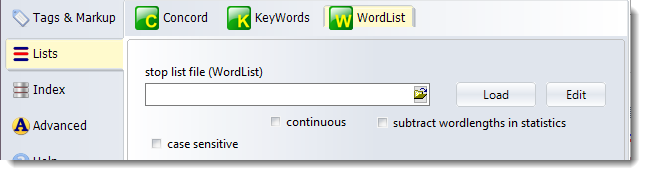
To choose your stop list, click the small yellow button in the screenshot, find the stop list file, then press Load. You will see how many entries were correctly found and be shown the first few of them. Here the Load button now shows a number, so it is in effect: that is, the 50 words in the list will be stopped from being included in a word list. Press Clear to deactivate it.

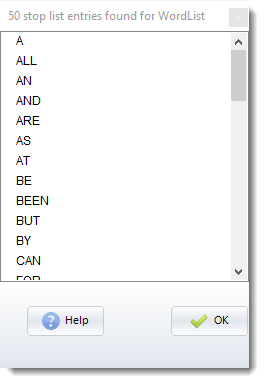
With a stop list thus loaded, start a new word list. The words in your stop list should now not appear in the word list.
Case Sensitive
If you have made a case-sensitive word list, you will probably want the stop list to be case sensitive too.
continuous
Normally, every word is read in while making the word list and stored in the computer's memory without checking whether it's the stop list. Eventually the set of words is checked in your stop list and omitted if it is present. That is much quicker. However, it means that for the most part, any statistics are computed on the whole text, disregarding your stop list.
If you choose continuous the processing will slow down dramatically since as every word is read in while making the word list, it will be checked against the stop list and ignored if found. In other words, every single case of THE and OF and IS etc. will be looked at as the texts are read in and sought in your stop list. The effect will be to give you detailed statistics which ignore the words in the stop lists.
subtract wordlengths in statistics
If you have not chosen continuous processing as explained above, you may want the statistics of your word list to attempt to deal in part with the stop list work done. With this choice, after the word list is computed, all the statistics concerning the number of types and tokens and 3-letter, 4-letter words etc. will be adjusted for the overall column (but not for the column for each single text) in your statistics.
See Match List for a more detailed explanation, with screenshots.
Another method of making a stop list file is to use WordList on a large corpus of text, setting a high minimum frequency if you want only the high-frequency words. Then save it as a text file. Next, use the Text Converter to format it, using stoplist.cod as the Conversion file.
stop lists in Concord
In the case of Concord a stop list can do two jobs: first, it will cut the stop list words out as collocates. Additionally it can cut out any stop list words as search-word hits: for example if you concordance beaut* and beautiful is in your stop list, any concordance lines containing beautiful will get cut out (those containing beauty will remain). For this to be activated, make sure you check the search-word box in the settings.

Stop lists
... are accessed via an Advanced Settings button in the Controller
See also: Making a Tag File, Match List, Lemmatisation.
