Mis-matched tags problem
well-formed text is like this:
<introduction>blah blah blah</introduction>
<body>blah blah blah</body>
<conclusion>blah blah blah</conclusion>
ill-formed text might be like this:
<introduction>blah blah blah</introduction>
<body>blah blah blah
<conclusion>blah blah blah</conclusion>
The body section of the text has no explicit end. Imagine for a corpus of text files you wanted to process Only Part of Text, specifying that you want both the introduction and the body, avoiding the conclusion of each. If you specified that you wanted from <introduction> to </body> something would go wrong, such as the ill-formed case getting missed completely or running on to include the conclusion.
Solution
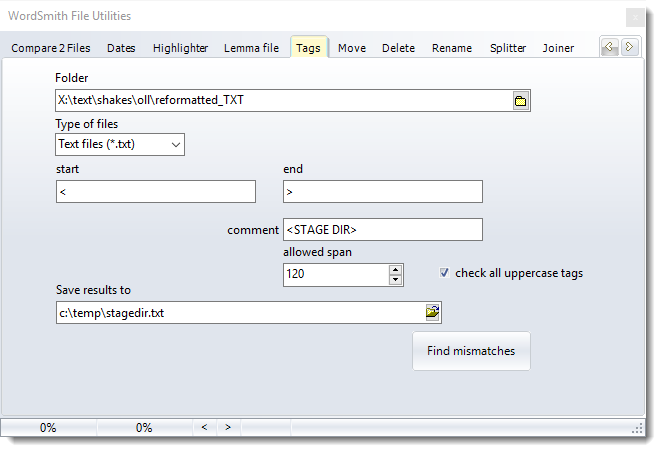
This procedure will examine all suitable text files and check whether every start has a corresponding end. Here we are checking all tags from < to >. If a tag is longer than the allowed span you get a warning.
The procedure checks any tag regardless of case but can optionally check all those in capitals especially thoroughly.
Check all uppercase tags
Checks tags if they are in capitals, looking out for mismatches (where a tag starts but doesn't end, for example) though allowing this within comment sections (here where there is a stage direction section marked <STAGE DIR>)
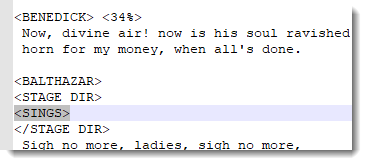
This report shows that in the play Much Ado About Nothing, within a section beginning <BENEDICT>, there is a tag <SINGS> which is not closed off (with </SINGS>). The tag context says this starts about 35% of the way through the text.
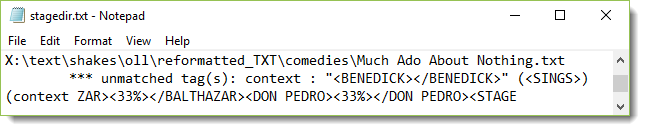
The cause of the mismatch has to be sought out. Here it is clear that <BENEDICT> starts but doesn't finish, because we get <BALTHAZAR> starting up with no sign of </BENEDICT>