
These settings affect how WordSmith will handle your texts. At the top, you see boxes allowing you to choose the language family (eg. English) and sub-type (UK, Australia etc.). These choices are determined by the preferences you have previously set. That is, the expectation is that you only work with a few preferred languages, and you can set these preferences once and then forget about them. You do this by pressing the Edit Languages button.
The choices below may differ for each language:
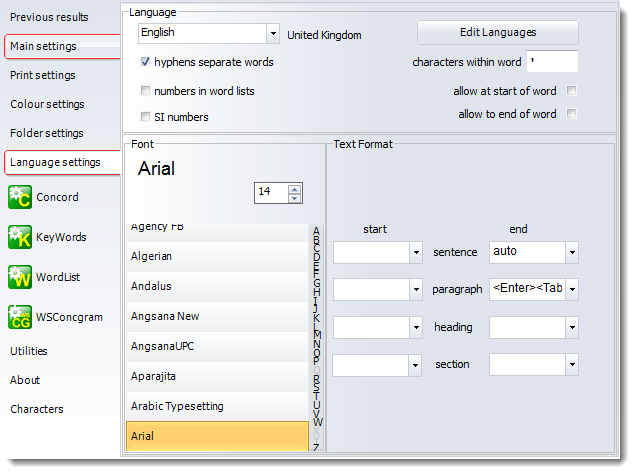
You can also specify whether hyphens are to count as word separators. If the hyphen box is checked [X], self-access will be treated as two words.
Should numbers be included in a word-list as if they were ordinary words? If you leave this checkbox blank, words like $300, 50.3M or 10th will be ignored in word lists, key words, concordances etc. and replaced by a #. If you switch it on, they will be included. SI numbers: the International System of Units (SI) stipulates that "Spaces should be used as a thousands separator (1 000 000) in contrast to commas or periods (1,000,000 or 1.000.000) to reduce confusion resulting from the variation between these forms in different countries." So numbers like 1,234,567.89 would be written 1 234 567.89. If you wish WordSmith to recognise such forms as one number each, leave this box checked, otherwise such a form in text would be counted as three successive numbers (1, 234, and 567.89).
WordSmith automatically includes as valid alphabetical symbols all those determined by the operating system as alphabetical for the language chosen. So, for English, A to Z and common accents such as é. For Arabic or Japanese, whatever characters Microsoft have determined count as alphabetic.
But you may wish to allow certain additional characters within a word. For example, in English, the apostrophe in father's is best included as a valid character as it will allow processing to deal with the whole word instead of cutting it off short. (If you change language to French you might not want apostrophes to be counted as acceptable mid-word characters.)
Examples:
' (only apostrophes allowed in the middle of a word)
'% (both apostrophes and percent symbols allowed in the middle of a word)
'_ (both apostrophes and underscore characters allowed in the middle of a word)
You can include up to 10.
If you want to allow fathers' too, check the allow to end of word box. If this is checked, any of these symbols will be allowed at either end of a word as long as the character isn't all by itself (as in " ' ").
For the Tools to count headings, they need to know how to recognise the start and end of one. If your text is tagged e.g. with <h1> and </h1>, type <h#> and </h#> in here. (# stands for any digit, ## for two, etc.) Whatever you type is case sensitive: </H#> is not the same as </h#>. (If you have HTML text which is not consistent, using sometimes </h1> and sometimes </H1>, then use Text Converter to make your texts consistent).
If these boxes contain eg. <div#> and </div>, the Tools will treat identify sections. Again, whatever you type is case sensitive.
If this space contains the word auto, the Tools will treat sentences as defined (ending with a full stop, question mark or exclamation mark, and followed by a capital letter), but if your text is tagged e.g. with <s> and </s>, type those in here. Again, whatever you type is case sensitive.
For the Tools to recognise paragraphs, they need to know what constitutes a paragraph start and/or end, e.g. a sequence of two <Enter>s (where the original author pressed Enter twice) or an <Enter> followed by a <Tab>. For that you would type <Enter><Tab>. If your text is tagged e.g. with <p> and </p>, you can type the tag in here. Case sensitive, too.
In many cases you may consider that defining a paragraph end will suffice (considering everything up to it to be part of the preceding one). Much HTML text does not consistently distinguish between paragraph starts and ends.
Note that spoken texts in the BNC use </u> instead of </p>, but you can leave </p> here as WordSmith will use </u> instead if the text has no </p> in it.
See also: Tagged Text, Stop Lists, Choosing a new language. Processing text in Chinese etc.
