
Each WordList display shows
•the word
•its frequency
•its frequency as a percent of the running words in the text(s) the word list was made from
•the number of texts each word appeared in
•that number as a percentage of the whole corpus of texts
•the word's dispersion
The Frequency display might look like this:
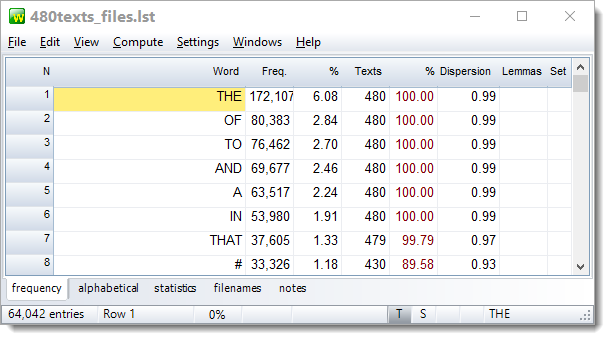
Here you see the top 8 word-types in a word list based on 480 texts. There are 172,107 occurrences of these words (tokens) altogether. The Freq. column shows how often each word cropped up (OF appeared 80,383 times in the 480 texts), and the % column tells us that the frequency represents 2.84% of the running words in those texts. The Texts column shows that OF comes in 480 texts, that is 100% of the texts used for the word list. It has a dispersion value of .99 showing that it is a word spread very evenly through the whole corpus of 480 texts.
Per 100, 1000 or million?
In advanced settings you can display the % column in different formats:
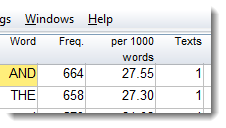
Another thing to note is that there seems to be a word #, with over 33 thousand occurrences. That represents a number or any word with a number in it such as EX658. If you want to see all such forms, change the number setting.
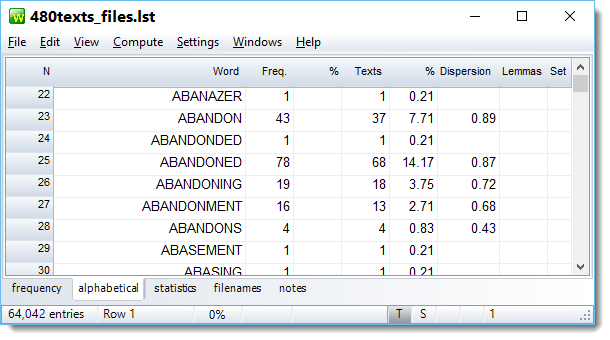
The Alphabetical listing also shows us some of the words but now they're in alphabetical order. ABANDON comes 43 times altogether, and in 37 of the 480 texts (less than 8%). ABANDONED, on the other hand, not only comes more often (78 times) but also in more texts (14% of them). They are similar in dispersion (their spread through the corpus of texts). As explained here, dispersion is not shown for words which have been lemmatised after the word list was computed.
Now let's examine the statistics.
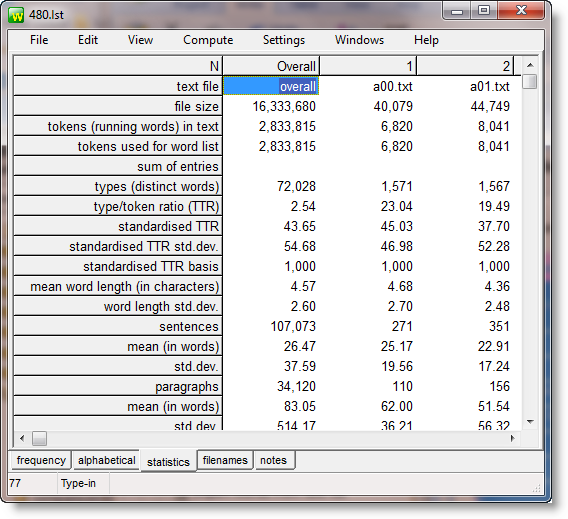
In all 480 texts, there are 72,028 word types (as pointed out above). The total running words is 2,833,815. Each word is about 4.57 characters in length. There are 107,073 sentences altogether, on average 26.47 words in length. In the text of a00.txt, there are only 1,571 different word types and that interview is under 7,000 words in length. This is explained in more detail in the Statistics page.
Finally, here is a screenshot of the same word list sorted "reverse alphabetically". In the part which we can see, all the words end in -IC.
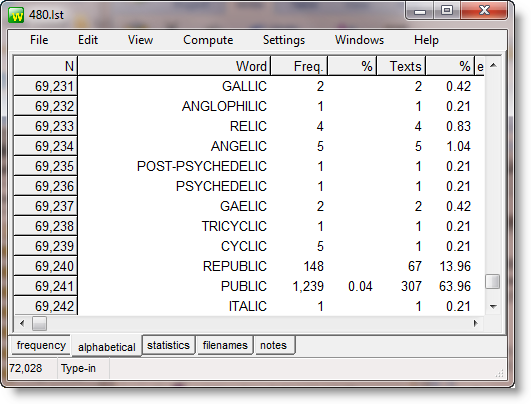
To do a reverse alphabetical sort, I had the Alphabetical window visible, then chose Edit | Other sorts | Reverse Word sort in the menu. To revert to an ordinary alphabetical sort, press F6.



See also : Consistency, Lemmatisation
