
The point of it…
You may choose to lemmatise all items in the current word-list using a standard text file which groups words which belong together (be -> was, is, were, etc.). It will be very useful if you want to lemmatise lots of word lists, and is much less "hit-and-miss" than auto-joining using a template.
There are English-language lemma lists at https://lexically.net/wordsmith/support/lemma_lists.html. And you can build your own easily if you have a corpus with lemma mark-up, for example the BNC.
How to do it
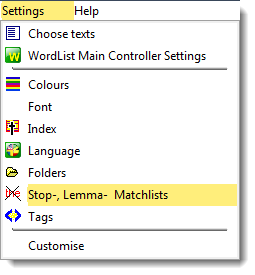
Lemma list settings are accessed via the Lists option in the WordList menu
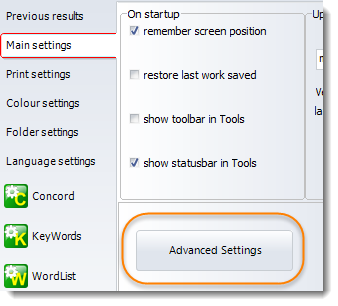
or an Advanced Settings button in the Controller
followed by
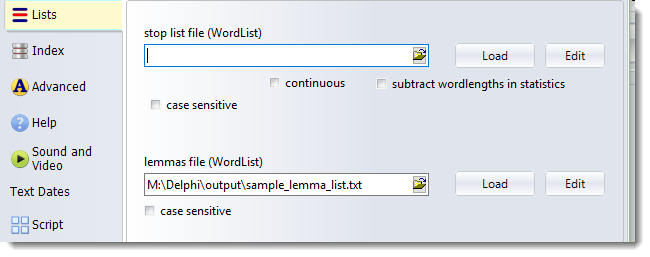
Choose the appropriate button (for Concord, KeyWords or WordList) and type the file name or browse for it, then Load it.
The file should contain a plain text list of lemmas with items like this:
BE -> AM, ARE, WAS, WERE, IS
GO -> GOES, GOING, GONE, WENT
WordSmith then reads the file and displays them (or a sample if the list is long). The format allows any alphabetic or numerical characters in the language the list is for, plus the single apostrophe, space, underscore. In other words, if you mistakenly put GO = GOES that line won't be included because of the = symbol.
A lemma list can be case sensitive: e.g. if using with a case sensitive word list.
The actual processing of the list will take place when you compute your word list, key word list or concordance or when you choose the menu option Match Lemmas ( ) in WordList, Concord or KeyWords. See Match List for a more detailed explanation, with screenshots. Lemmatising occurs before any stop list is processed.
) in WordList, Concord or KeyWords. See Match List for a more detailed explanation, with screenshots. Lemmatising occurs before any stop list is processed.
What if my text files don't contain the headword of the lemma?
Suppose you are matching AM, ARE etc with BE as in the list above, but your texts don't actually contain the word BE. In that case the tool will insert BE with zero frequency and add AM, ARE etc as needed.
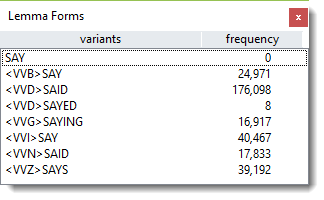
In this screen-shot the form SAY is shown with zero frequency. That's because all the data had <VV> mark-up. No case of SAY without mark-up was present but the lemma file specified SAY as the head word, so a new entry showing the head word gets created.
See also: Lemmatisation, Building a lemma file, Match List, Stop List, Lemmatisation in Concord
