
What is XML?
XML text has angle-bracketed mark-up which provides additional information. For example the British National Corpus has text which is structured like this:
<s n="43">
<w c5="PNP" hw="i" pos="PRON">I </w><w c5="VVB" hw="mean" pos="VERB">mean</w>
<c c5="PUN">, </c><w c5="AVQ" hw="where" pos="ADV">where </w>
<w c5="VDB" hw="do" pos="VERB">do </w><w c5="NN1-VVG" hw="eating" pos="SUBST">eating </w>
<w c5="NN2" hw="disorder" pos="SUBST">disorders </w>
<w c5="VVB" hw="come" pos="VERB">come </w><w c5="PRP" hw="from" pos="PREP">from</w>
<c c5="PUN">?</c>
</s>
<s> ... </s> signals a sentence.
<w c5="PNP" hw="i" pos="PRON"> signals that the next word is a pronoun (coded PNP), head-word is "i",
<w c5="NN2" hw="disorder" pos="SUBST"> signals that the next word is a plural noun belonging to the head-word "disorder" and it's a substantive.
c5="NN2" is an attribute of the <w start-tag, hw="disorder" is another attribute. There can be many attributes in a start-tag. The <c start-tags have only one, but the <w start-tags have 3 in this BNC text.
WordSmith's handling of XML
By default, WordSmith simply ignores all the mark-up so a word list will only get the words in black inserted in it, a concordance will only see those words (I mean, where do eating disorders come from?).
If you define a tag file with colours you can get views like

Searching using Attributes
If you want to search for all instances of NN2 forms (plural nouns), you'd need to type
<w c5="NN2" * *>*
as your search-word and answer yes to the question as to whether you're concordancing on tags.
You would get results like this:

Lots of mark-up! See here for a better solution where you define the tags you're interested in first.
Hide the mark-up
If you prefer not to see all that mark-up in grey, choose to hide the undefined mark-up
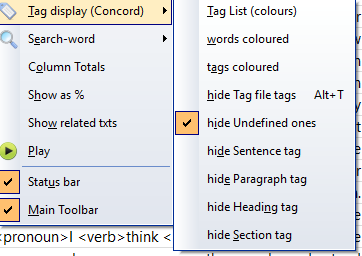
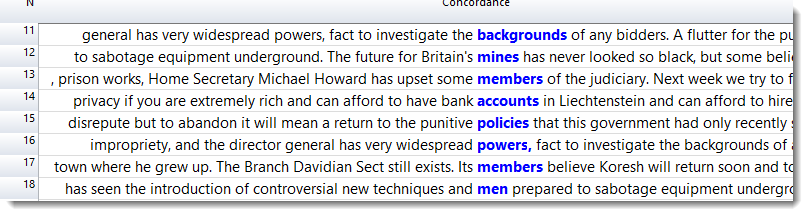
There is a box in the main tool which can show or hide mark-up, too.
Asterisks in your search-word
In the example above, we search on
<w c5="NN2" * *>*
<w because each start-tag where NN2 forms are found starts with <w and the very first attribute is c5="NN2". Then two asterisks to indicate that we aren't interested in the hw or pos attributes. Then a closing > and another asterisk because the word which follows will be right next to the > in our corpus.
For two successive parts of speech,
<w c5="AT0" * *>* <w c5="NN1" * *>*
looks for any article (the/a/an) followed by any singular count noun.
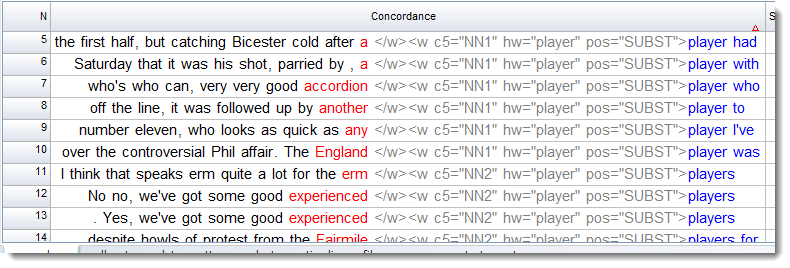
A search on
<w c5="NN?" hw="player" *>*
where we are allowing NN1 or NN2 and requiring the hw to be player,gets results like this:
Another example
Searching Italian .XML containing text like this:
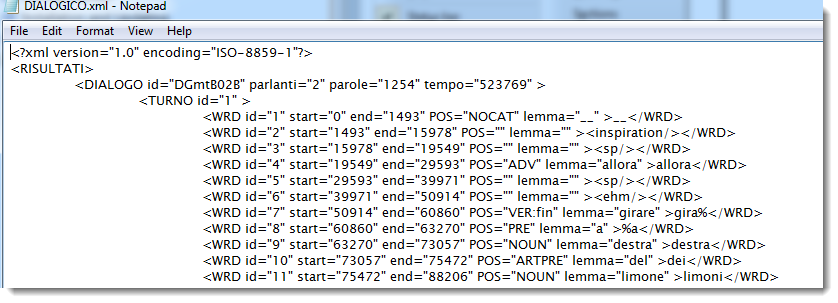
and wishing to find all cases of the ARTPRE part of speech, with the search-word specified like this
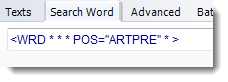
and answering yes to this:
we get a considerable concordance with entries like this:

(I have no idea why there are % symbols in the source .XML, by the way.)
See also : Handling the BNC
