|
コロケートと相互情報量
|

|

|

|
|
コロケートと相互情報量
|
|
|
|
次の例では、BNC の書き言葉セクションから抽出された「AGO」のコロケートが頻度順に示されています。
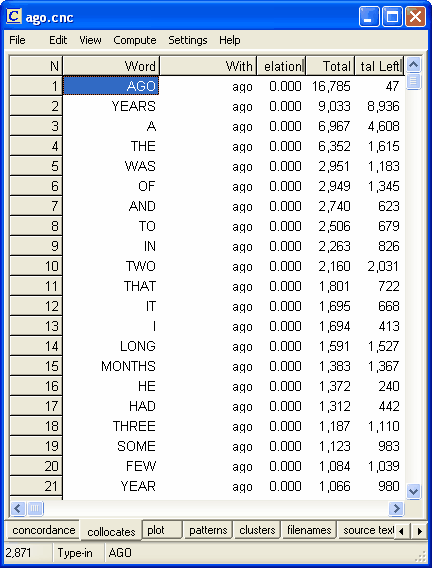
「AGO」のインスタンスは 17,000 近くあること、そして「YEARS」が最多のコロケートで、「AGO」の付近に 9,000 回も出てきていることがわかります。"Relation" の列は空白なので、この段階で可能なのは頻度順かアルファベットの語順に並べ替えることだけです。ここで知りたいのは、「AGO」のコロケートのそれぞれが、どれほどの近さでこの語に関係しているかを知る方法です。「A, THE, WAS」などは、本当に「AGO」と近い関係にあるのでしょうか?
メニュー・バーから[Compute → Mutual Information]を選択し、

比較のための適切な単語リストを選択します。
そして、[Relation]の列でソートをかけると、次のようなリストが得られます。
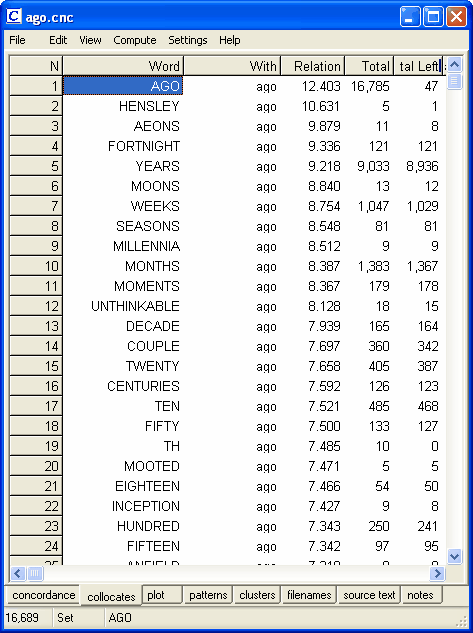
リストの上位に示されたアイテムは、時間的にも数量的にも「AGO」の付近に現れる傾向をよりよく反映したものとなっています。[一番上位のコロケート(HENSLEY)が「 AGO」と一緒に出てきたのは5回だけです(BNC の書き言葉セクション全体の中での総数は 17)]
Page url: http://www.lexically.net/downloads/version5/HTML/?collocatesandmutualinformation.htm

