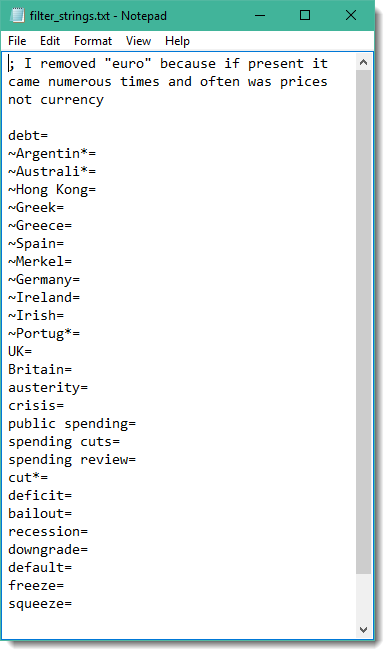
The point of it
A function to let you separate out texts which meet specific requirements. The procedure computes a score for each text based on whether it contains certain words or phrases or not. Some words count positively, others (which you want to exclude in the filter) count negatively. Eventually you can separate out all texts which score above some threshold.
How to do it

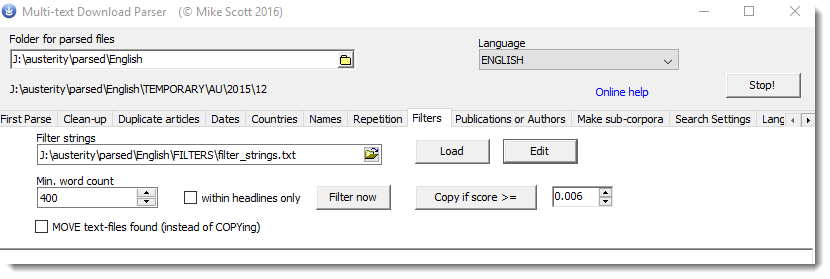
Minimum word count
This is a simple method for avoiding excessively short texts.
This process also counts the spread of hits over the text. The text is notionally split into three segments and the hits must be spread over all of these segments.
Headlines search
If you check the within headlines only box, the search will be carried out only within the headlines text.
Filter now
Press this button to get your texts scored. What happens is each text is read, its words counted after stripping out any mark-up, and then each of the filter strings get searched for. The number of occurrences of each word or phrase is computed.The final score computed is the number of positive hits minus the number of negative hits (with ~), plus a computation of the amount of spread within the article where one extra point is given for each 33% of the text the hits are found in. Finally the total gets divided by the word count of the whole article.
The resulting list shows you each original article, plus its score (0.083 for the first article) and its word count (604).
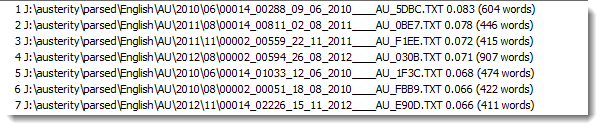
at the bottom of the list we get negative scores such as -0.061. Not enough positive words were found and a lot of the unwanted ones were present.



Copy if score >=
If you press the Copy if score >= button, the program will copy any of the texts whose scores are equal to or greater than the value in the box, to a sub-folder of the FILTERS sub-folder. (If MOVE text-files is checked any filtered texts get moved, not just copied.) So you will find the article in a sub-folder of your parsed data matching the structure of each original article.
>