relationships computing

Contents
To compute these relationship statistics you need a WordList Index. Then in its menu, choose Compute | ![]() Relationships.
Relationships.
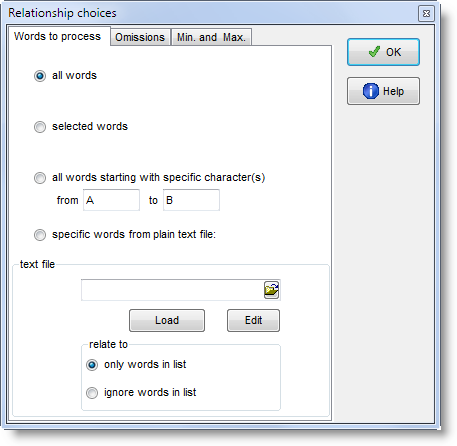
You can choose whether to compute the statistics for all entries, or only any selected (highlighted) entries, or only those between two initial characters e.g. between A and D, or indeed to use your own specified words only. If you wish to select only a few items for MI calculation, you can mark them first (with
Alternatively you may choose to use only items from a plain text file constructed using the same syntax as a match-list file., or to use all items except ones from your plain text file.
|
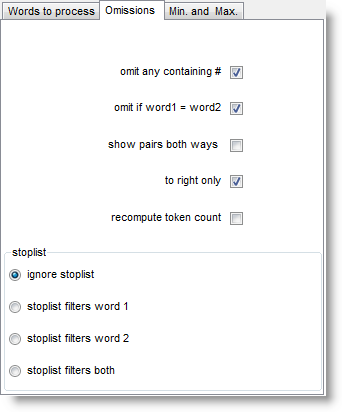
omit any containing # will cut out numbers, and omit if word1=word2 is there because you might find that GOOD is related to GOOD if there are lots of cases where these 2 are found near each other.
show pairs both ways allows you to locate all the pairs more easily because it doubles up the list. For example, suppose we have a pair of words such as HEAVEN and EARTH. This will normally enter the list only in one order, let us say HEAVEN as word 1 and EARTH as word 2. If you're looking at all the words in the Word 1 column, you will not find EARTH. If you want to be able to see the pair as both HEAVEN - EARTH and EARTH - HEAVEN, select show pairs both ways. Here we can see this with DUST and WITH
to right only: if this is checked, possible relations are computed to the right of the node only. That is, when considering DUST, say, cases of WITH to the right will be noticed but cases where WITH is to the left of DUST would get ignored.
Here, the number of texts goes down to 5 from 9, MI score is lower, etc, because the process looks only to the right. (In the case of a right-to-left language like Arabic, the processing is still of the words following the node word.) recompute token count allows you to get the number of tokens counted again e.g. after items have been edited or deleted.
|


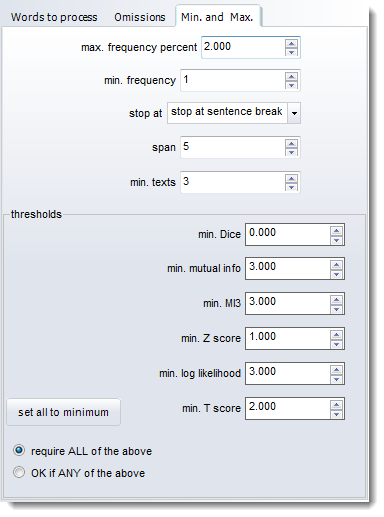
max. frequency percent: ignores any tokens which are more frequent than the percentage indicated. Set the maximum frequency, for example, to 0.5% to cut out words whose frequency is greater than that.(The point of this is to avoid computing mutual information for words like the and of, which are likely to have a frequency greater than say 1.0%. For example 0.5%, in the case of the BNC, would mean ignoring about 20 of the top frequency words, such as WITH, HE, YOU. 0.1% would cut about 100 words including GET, BACK, BECAUSE. If you want to include all words, then set this to 100.000) min. frequency: the minimum frequency for any item to be considered for the calculation. (Default = 5; a minimum frequency of 5 means that no word of frequency 4 or less in the index will be visible in the relationship results. If an item occurs only once or twice, the relationship is unlikely to be informative.) stop at allows you to ignore potential relationships e.g. across sentence boundaries. It has to do with whether breaks such as punctuation or sentence breaks determine that one word cannot be related to another. With stop at sentence break, "I wrote the letter. Then I posted it" would not consider posted as a possible collocate of letter because there's a sentence break between them. span: the number of intervening words between collocate and node. With a span of 5, the node wrote would consider the, letter, then, I and posted as possible collocates if stop at were set at no limits in the example above. min. texts: the minimum number of texts any item must be found in to be considered for the calculation. min. Dice/mutual info.MI3 etc: the minimum number which the MI or other selected statistic must come up with to be reported. A useful limit for MI is 3.0. Below this, the linkage between node and collocate is likely to be rather tenuous. Choose whether ALL the values set here are used when deciding whether to show a possible relationship or ANY. (Each threshold can be set between -9999.0 and 9999.0.) |
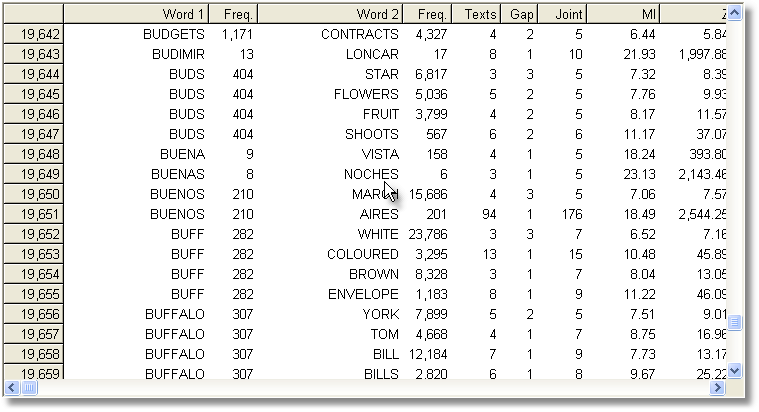
Computing the MI score for each and every entry in an index takes a long time: some years ago it took over an hour to compute MI for all words beginning with B in the case of the BNC edition (written, 90 million words) in the screenshot below, using default settings. It might take 24 hours to process the whole BNC, 100 million words, even on a modern powerful PC. Don't forget to save your results afterwards!
See also Collocates, Mutual Information Settings, Mutual Information Display, Detailed Consistency Relations, Making an Index List, Viewing Index Lists, Recompute Token Count, WordList Help Contents.