
Display
The collocation display initially shows the collocates in frequency order.
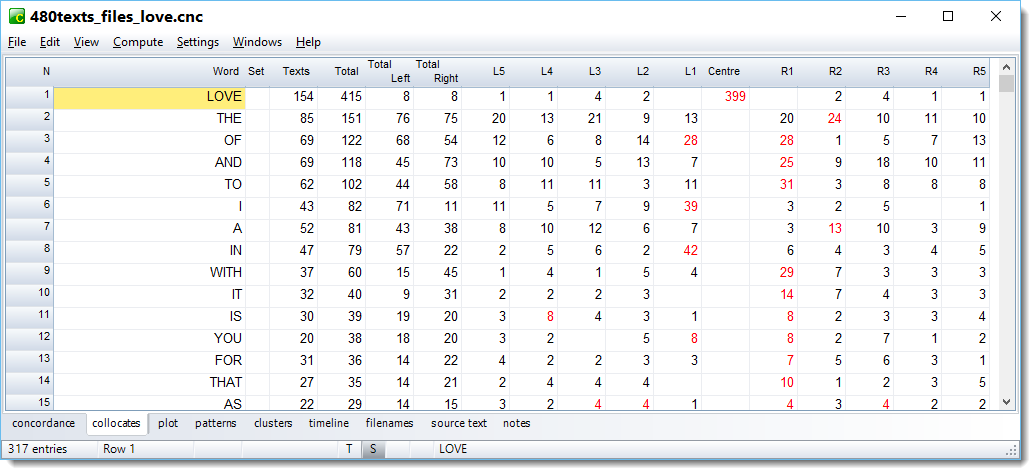
You will see the details of how many cases of each collocate come with the search word. The search-word itself will be included, here it's love. The word of occurs 28 times immediately right of love, in L1 position.
The number of words to left and right depends on the collocation horizons.
The numbers are:
the total number of times the word was found in the neighbourhood of the search word
the total number of times it came to the left of the search-word
the total number of times it came to the right of the search-word
a set of individual frequencies to the left of the search word (5L, i.e. 5 words to the left, 4L .. 1L)
a Centre column, representing the search-word
a set of individual frequencies to the right of the search word (1R, 2R, etc.)
The number of columns will depend on the collocation word horizons. With 5,5 you'll get five columns to the left and 5 to the right of the search word. So you can see exactly how many times each word was found in the general neighbourhood of the search word and how many times it was found exactly 1 word to the left or 4 words to the right, for example.
Red numbers
These are the highest numbers within the context horizons. L4 is shows up red because 8 occurrences in L4 position is the highest in the range L5 to R5.
Relationships
If you compute relationships you can get to see which collocates are most strongly related to the search-word.
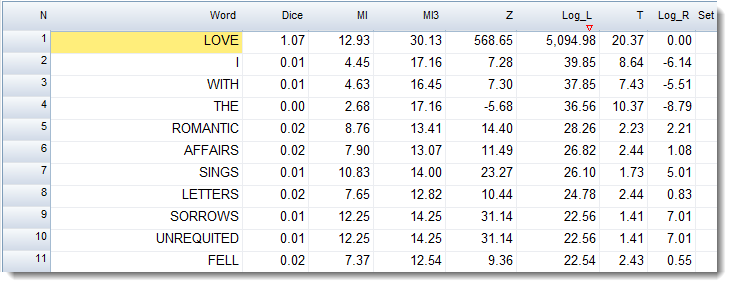
New columns appear showing 9 different statistics which might help us find words somehow linked to love.
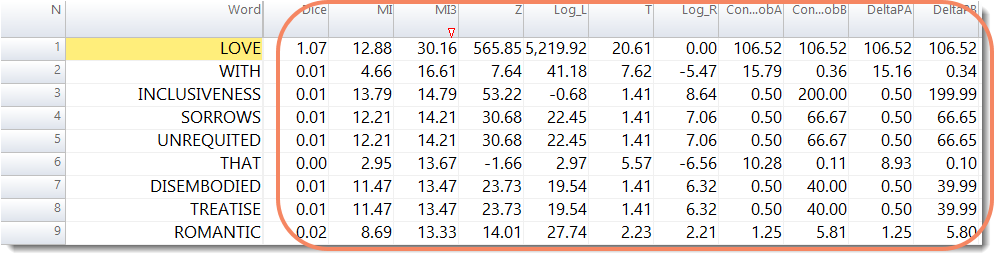
Same data, different statistic: a rather different impression.
Sorting etc.
The frequency display can be re-sorted ( ) and you can recalculate the collocates (
) and you can recalculate the collocates ( ) if you zap entries from the concordance or change the horizons.
) if you zap entries from the concordance or change the horizons.
You can also highlight any given collocate in your concordance display.
See also: Word Clouds, Collocation, Collocation Relationship, Collocates and Lemmas, Mutual Information
