
The point of it...
The idea is to find out how strongly each collocate relates to the search-word near which it was found.
Suppose you have made a concordance on the word love. You see lots of high frequency collocates, mostly grammar words. These are the top frequency collocates but they are words which collocate with almost any search-word..... What you might want to know is which words are specially linked to love.
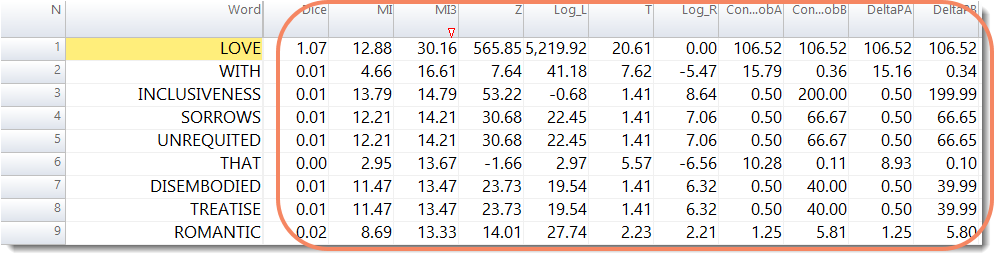
Here we see them sorted according to their MI3 scores. In this particular corpus we get Love and sorrows, love and unrequited. Sad!
Looking to the right, the DeltaPA score shows a much higher link between LOVE and WITH than between WITH and LOVE (DeltaPB score). (If you discuss love you may well say who someone is in love with, but if you mention with, you mostly are not talking about love.) And SORROWS predicts LOVE but LOVE doesn't predict SORROWS. (Why? Because in this corpus sorrows comes only 3 times two of which collocate with love, but there are lots of contexts of love without sorrows (397 out of 399) So maybe it isn't so sad, really.
How to compute it
In the Concord menu, choose Compute | Relationships:
1.If you haven't done so yet, use WordList to make a word list of the same text files.
2.Now choose the Relationships menu item  and Concord will look up each of your collocates in the word list and compute a set of relationship statistics using the information in the reference corpus word list.
and Concord will look up each of your collocates in the word list and compute a set of relationship statistics using the information in the reference corpus word list.
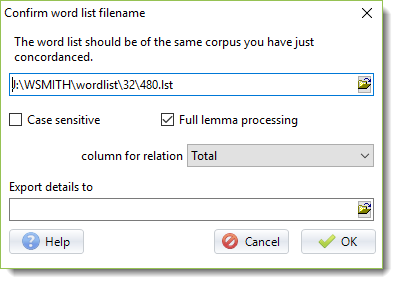
Full lemma processing, case sensitive
These are only relevant if your word list has any lemmatised entries, or it is a case-sensitive word list and you wish processing to respect case-sensitivity. If full lemma processing is checked, each individual joined form will be checked in the relationships computation.
Column for relation
The default is "Total". If you choose Total you're computing the relationship across the current collocation horizons set.
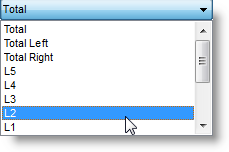
If you prefer to examine the relationship at only one position instead, you may:
Export Details to
You can optionally choose a file to save details to. This will contain the numbers the statistics are based on and you could take the results into Excel to compute your own statistics.
See also: Collocation, Collocate display, Mutual Information and other relationship statistics, Collocates and relative entropy
