
The point of it
You might want to process only the speech of elderly men, or only advertising material, or only classroom dialogues. This function allows WordSmith to search through each text, e.g. in text headers, ensuring that you get the right text files and skip any irrelevant ones.
Suppose you have a large collection of texts (e.g. the British National Corpus) and you cannot remember which of them contain English spoken by elderly men.
Knowing that the BNC uses stext> for spoken texts, sex=m for males, age=5 for speakers aged 60 or more, you can get WordSmith to filter your text selection. It will search through the whole of every text file (not just the tags or header sections, in fact the first 2 megabytes of the file) to check that it meets your requirements.
You can specify up to 15 tags, each up to 80 characters in length. They will be case sensitive (i.e. you will get nothing if you type Age=5 by mistake).
Horizontally, the options represent combinations linked by "or". Vertically, the combinations are "and" links. The bottom set represents "but not" combinations.
After your text files have been processed, you will be able to see which met your requirements in the Text File choose window and can save the list for later use as favourites.
Examples:
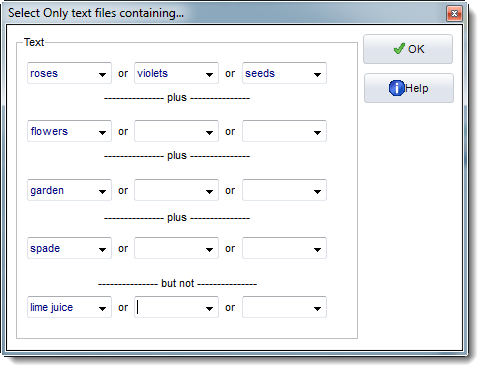
You only want text files which contain either roses or violets or seeds, and flowers must be present too, so must garden and spade But you do not want lime juice to be present in the text.
If you want book or hotel but only if they're not in a text file containing publish or Booker Prize: write book into the first box, hotel in the box beside it, and publish* and Booker * in the first two boxes in the bottom row.
If you want to know which text files met your criteria and which did not you can choose save text file data in the Advanced options.
See also: Tags as Selectors, Selecting within texts, Extracting text sections, Filtering your text files using Text Converter, Guide to handling the BNC
