
You can get WordSmith to use tags to select one section of a text and ignore the rest. This is "selecting within texts". You can also select between texts: that is, get WordSmith to look within the start of each text to see whether it meets certain criteria.
These functions are available from Main Settings | Advanced | Tags | Only If Containing or Only Part of File.
Defaults
The defaults are: select all sections of all texts selected in Choose Texts but cut out all angle-bracketed tags.
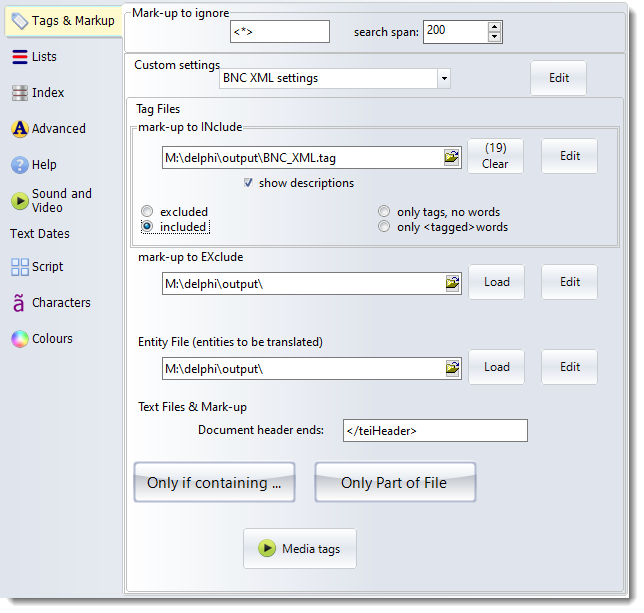
 The order in which these choices are handled
The order in which these choices are handled
See also: Overview of Tags, Making a Tag File, Tag Handling, Tag Concordancing, Showing Nearest Tags in Concord, Viewing the Tags, Types of Tag, Guide to handling the BNC, XML text
